Part 6
In part 4 we explored named routes. In this session we move onto Rails’ REST.
Part 5
The Critics
Before we begin you should know that there are many critics of the Rails implementation of REST. There are many reasons for arguments against Rails’ REST e.g. Rails uses server side session state and client side cookies. Some people say that this is not REST compliant. Rails’ REST might not be 100% REST compliant, but you can still benefit from using REST in your Rails applications. In The Rails Way, Obie Fernandez explains that the benefits from using Rails’ REST fall into two categories:
- Convenience and automatic best practices for you
- A REST interface to your application for the rest of the world
Therefore it is worth learning and using Rails’ REST.
The Standard Introduction
Representational State Transfer (REST) is an architectural style. It was first introduced by Roy Fielding in his PhD thesis. Roy Fielding is one of the principal authors of HTTP.
The Mindset
When developing a Rails application in the RESTful way it helps to change your mindset. You should not think that you are developing a web site for users accessing the site via a browser. It is better to think of the application as being a service. The service performs actions for clients. These clients may be humans or other machines on the network.
This service will typically be placed on the internet. Therefore we could call it a web service. When I hear the term web service I immediately start thinking about SOAP and all the WS-* specifications. Let’s be clear, we are not talking about ‘those’ web services. We are talking about RESTful web services. These two technologies provide similar functionality, but RESTful web services are simple and sensible.
The Terminology
As previously stated, programming in REST requires a change in the way we think about the system. This naturally leads to a change in the way we talk about the system. The following provides a brief description of some of the key terms used in discussions about REST and HTTP.
A resource is one of the key concepts in REST. Many discussions on REST claim that a resource is anything and everything. This is neither true nor helpful. Let’s examine this concept with the aid of an example.
Let’s assume that the music store has started selling albums. The database may have the following schema:
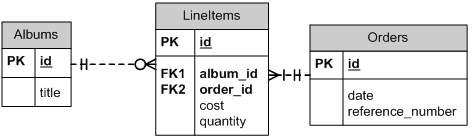
The data in the database is the raw data. There is data which, given in isolation, is of no real value to a client. For instance it is unlikely that a client will want only one row from the LineItems table. This means that a LineItem (on its own) is not a resource within the context of the music store service.
A client would want all the information pertaining to an order. This would include data from one or more tables. Some data would not be included e.g. database keys. Some information may be added e.g. the total cost of the order might be calculated and included in the ‘order information’. This ‘order information’ is an example of a resource. Order resource is the type, there will be one order resource instance for each order made.
Each resource must be given a globally unique identifier. This is done using a URI. This could look like this:
http://www.example.com/orders/65
A client, in an admin role, may want a list of all the orders. This collection of orders would be another resource. Following the REST architecture, the orders resource would be assigned the following URL:
http://www.example.com/orders
It is important to note that these resources are not HTML documents. Roy Fielding describes a resource as a conceptual mapping. As a resource is a conceptual entity it can not be used by a client. The service provides the client with a representation of the resource.
When the client is a browser, the service typically provides an HTML representation of the resource. If the client is another machine then the service may provide an XML representation of the resource. Other representations could include a PDF file, an image, csv etc. A representation is only supported by the service if it is applicable and required.
Resources are often referred to as nouns. This is often done when talking about HTTP to assist learning. The term ‘noun’ is more abstract. For our purposes, resources and ‘nouns’ are synonymous.
HTTP also has the notion of verbs. These are the HTTP operations. We are all familiar with the POST and GET operations. In addition to these two operations, HTTP also supports: DELETE and PUT.
There are a few more terms to cover, but we can do that later. The core terms have been explained.
Continue reading →




